

- Детаљи
- Read Time: 1 min
Пројектом наше библиотеке "Креирање мултимедијалне текстуално претраживе дигиталне колекције коришћењем и унапређењем најновије технологије вештачке интелигенције и машинског учења" који је подржало Министарство културе предвиђено је и додатно обучавање модела за аутоматско препознавање говора за српски језик. Након неколико месеци припрема и обуке објављена је побољшана верзија модела вештачке интелигенције Whisper, коју је објавила компанија OpenAI у септембру 2022. године.
Побољшана верзија доступна је на порталу Huggingface, специјализованом за рад и публиковање материјала везаних за вештачку интелигенцију и машинско учење. WER односно проценат грешке на нивоу речи овог модела је 5,5% за српски језик у ћириличном писму.
Модел је доступан на ОВОМ ЛИНКУ.
Рад са овим моделом захтева хардверску подршку са графичком картицом од минимум 10Gb RAM меморије, што представља већи издатак. Захваљујући оптимизованим решењима које су имплементиране у софтвере за обраду титлова, овај модел можете тестирати и на рачунару без посебне графичке картице. Оптимизован модел под називом Faster Whisper доступан је на ОВОМ ЛИНКУ.
Модел можете тестирати на следећи начин.
Инсталирајте програм Subtitle Edit (минимум 4.0.2) са ОВОГ ЛИНКА
У овом програму постоји опција за креирање титлова до које се долази на следећи начин:
Кликните на Video и у менију изаберите Audio to text (Whisper)
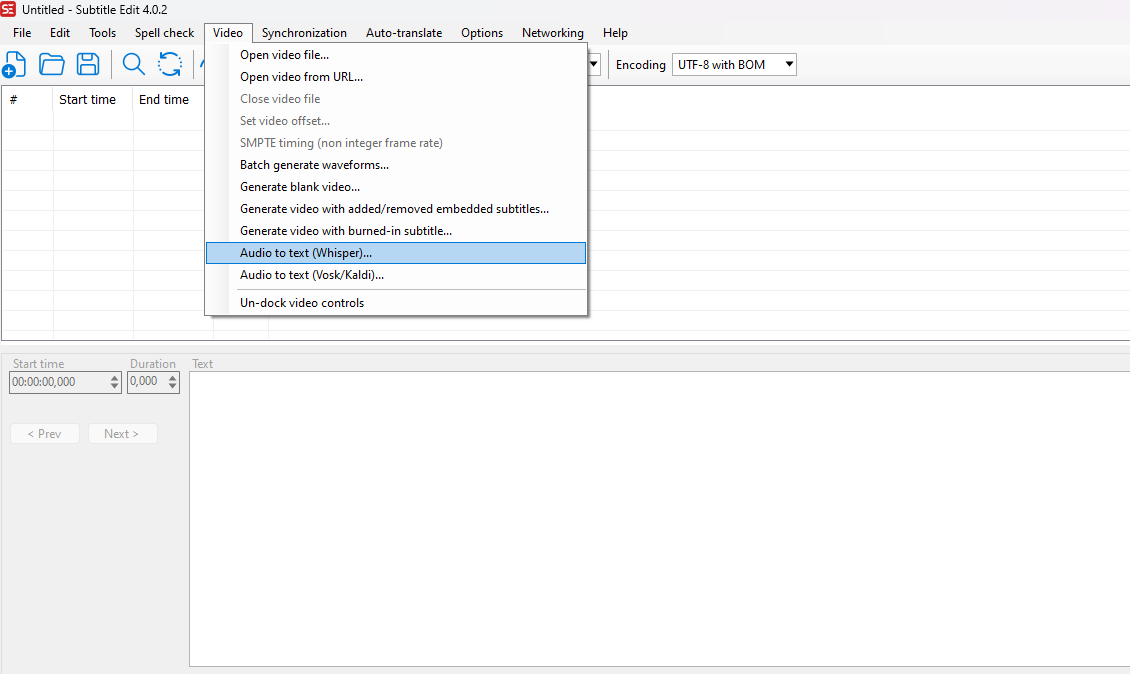
Када кликнете на ову опцију отвара се слећи прозор и у горњем десном углу изаберите опцију "Purfview's Faster-Whisper"
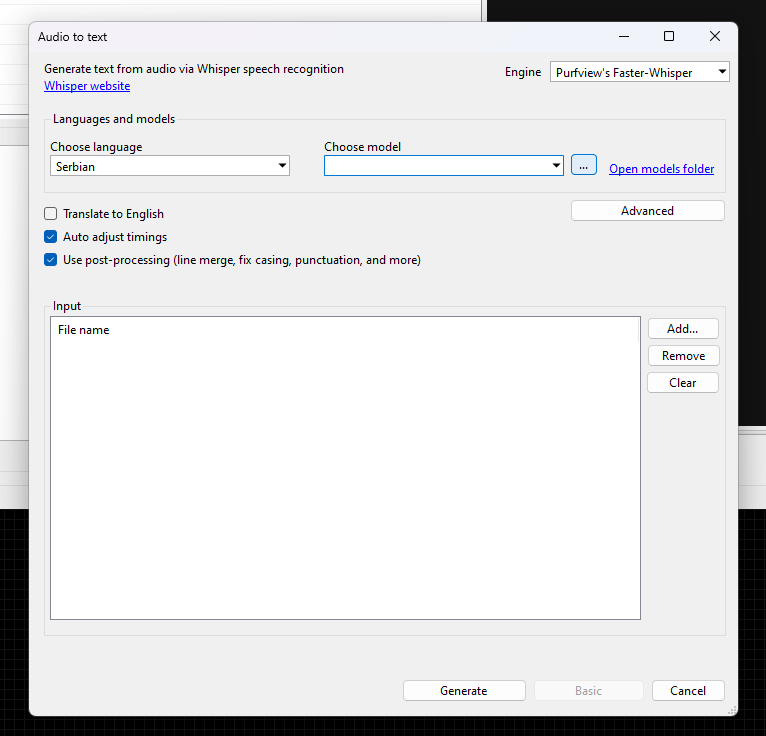
Поред опције "Choose model" кликните на квадрат са три тачкице, отвара се поље за преузимање модела и изаберите модел "Large-v3"
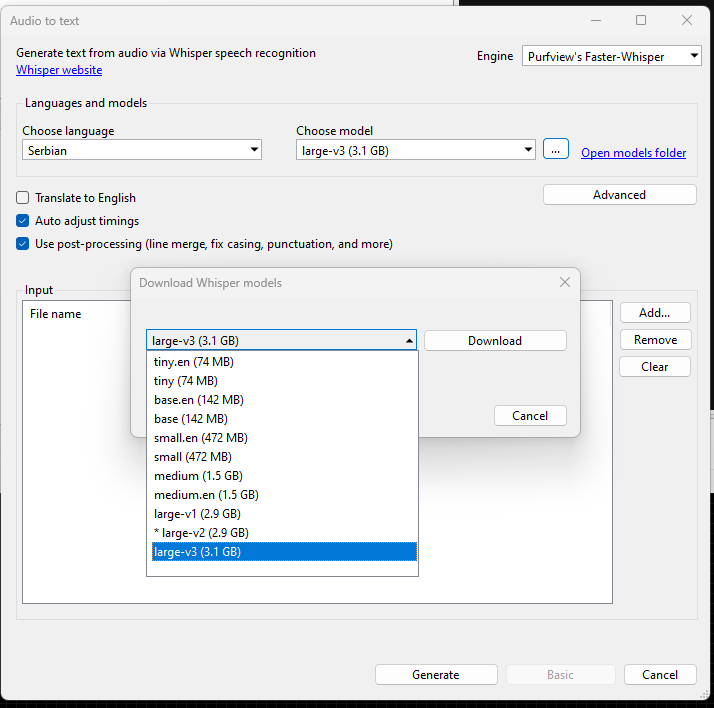
Кликните на Download, програм ће преузети главни модел, када је модел преузет кликните на "Open models folder"
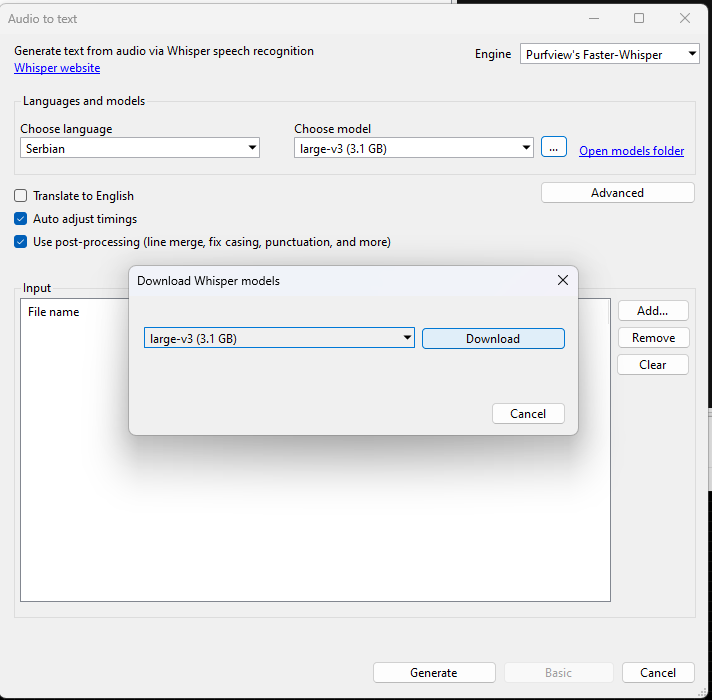
Отвориће се фолдер са моделима које сте преузели, отворите овај фолдер као на слици
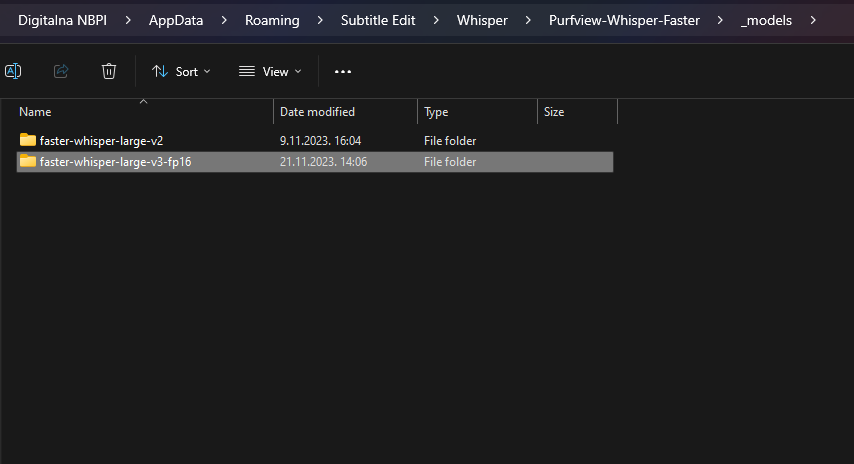
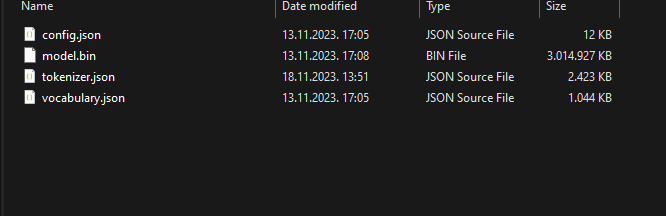
у том фолдеру налазе се фајлови које треба заменити са нашим моделом (можете их обрисати)
Преузмите фајлове нашег модела са ОВОГ ЛИНКА
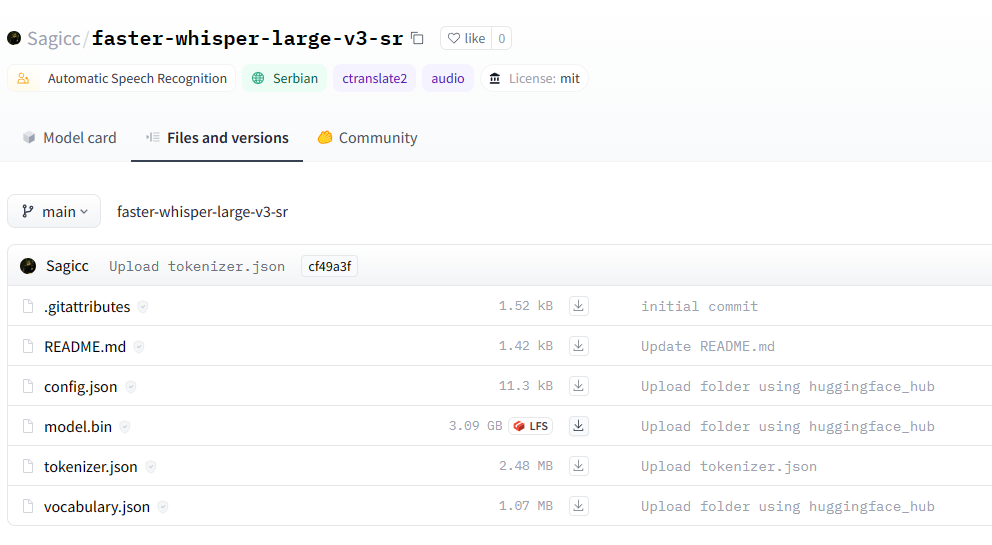
config.json
model.bin
tokenizer.json
vocabulary.json
ове фајлове снимите у фолдер који сте креирали на рачунару, копирајте ове фајлове у фолдер који сте отворили у програму (предходна слика).
Програм је спреман за рад. Када радите транскрипт опција је Video -> Audio(Whisper), као на слици изаберите језик, модел и Faster-Whisper у горњем десном углу.
Велико хвала колеги Милану Јовановићу из Народне библиотеке Пирот који нам је уступио илустрације и што нам је помогао у тестирању овог модела.



